There is a lot of noise about huge investments poured into datacenters. The tendency is to believe that deploying a Large Language Model (LLM) on-premise requires enterprise-grade infrastructure and huge GPU clusters. And especially… deep pockets. That might be true if you’re trying to compete with OpenAI.
But if your goal is to build a secure, private, and cost-efficient environment for internal use, the reality is very different.
You don’t need millions. You just need a pragmatic architecture.
At Itsavirus, we’ve been building private LLM environments for clients who want to bring generative AI inside their own walls — for compliance, privacy, or performance reasons. What we’ve learned is that success has little to do with model size or hardware power. It’s about making the right trade-offs.
Before choosing a model or GPU, ask what you actually need.
Clarity here defines everything that follows. Once you stop trying to imitate OpenAI or Anthropic, you can build something lean, efficient, and reliable.
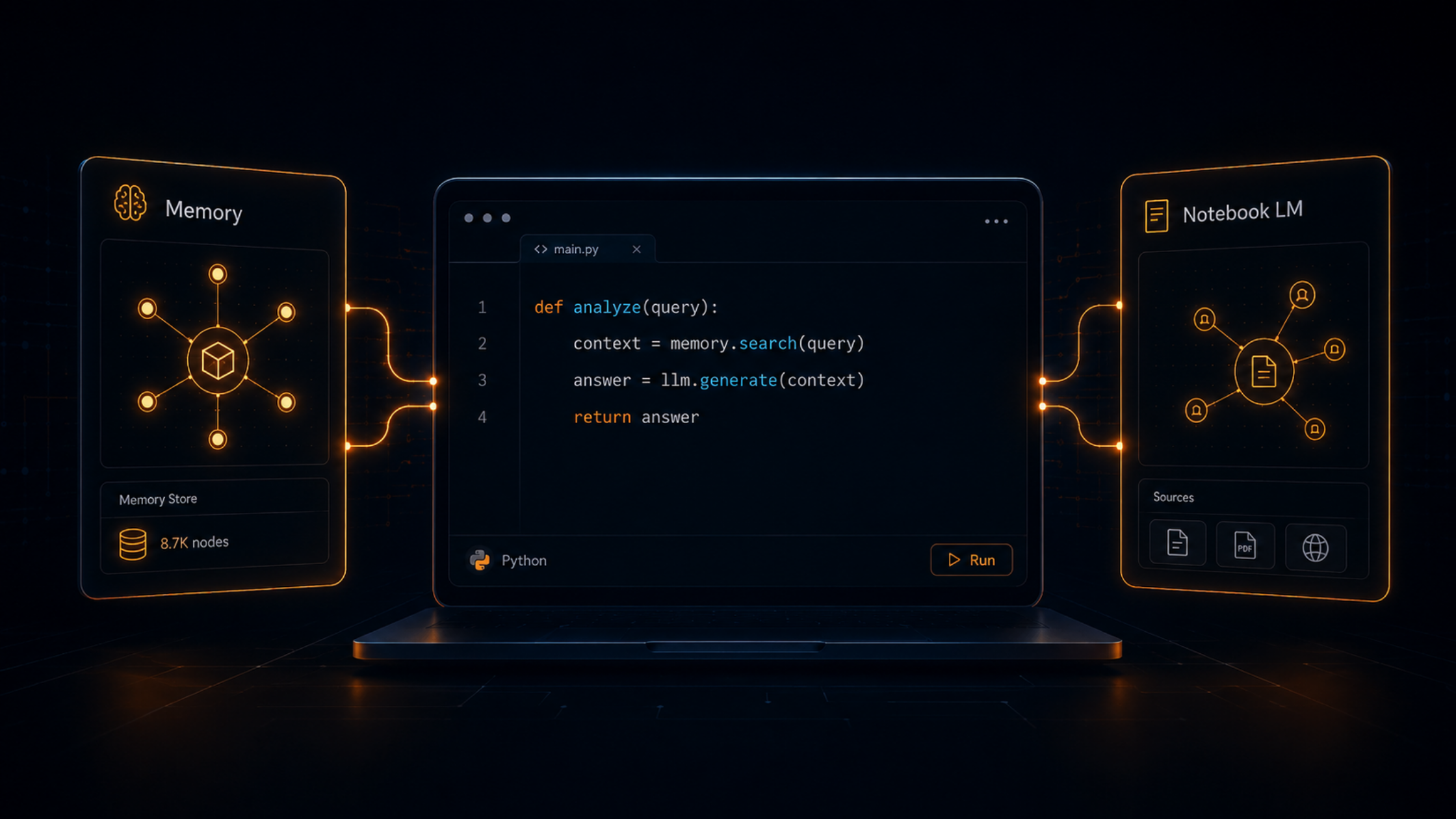
A minimal but production-ready LLM environment usually consists of four layers:
Model layer – Choose a model that fits your task. For many enterprise applications, a 7B-parameter model (like Mistral, Llama 3, or Phi-3) delivers exceptional results when properly fine-tuned.
Inference layer – Use an inference gateway such as vLLM, Text Generation Inference (TGI), or Ollama to manage requests, caching, and batching. This layer is where you gain efficiency and stability.
Integration layer – Expose APIs or SDKs that connect your model to business systems: chat interfaces, CRMs, knowledge bases, or workflows.
Security & infrastructure layer – Deploy within your Virtual Private Cloud (VPC) or internal data center. Use container orchestration (Docker, Kubernetes) to scale safely and apply access control through IAM policies or VPN.
Here’s where the myth begins to fade.
A single, well-chosen GPU can take you very far.
Take the NVIDIA RTX A6000 (48GB VRAM) as an example. It can comfortably run a 7B-parameter model with low latency and handle hundreds of daily queries for internal applications. Pair it with an AMD Threadripper or Intel Xeon CPU, 128GB of RAM, and fast NVMe storage, and you have a capable inference server that fits inside a small rack.
If you need redundancy or higher throughput, you can easily scale horizontally with multiple A6000s or A100s. The key is architecture before hardware — design for load and latency, then add GPUs only where necessary.
Here’s what an on-prem LLM setup might look like for a small or mid-size organization:
ComponentDescriptionEstimated Cost (USD)NVIDIA RTX A600048GB VRAM GPU4,500 – 6,000Server chassis & CPUThreadripper or Xeon, 128GB RAM3,000 – 4,000Storage & NetworkingNVMe drives, 10GbE1,000Software stackOpen-source models + inference gatewayFreeContainer orchestrationDocker or KubernetesFreeTotal≈ $8,000–10,000
That’s not a toy setup — it’s a private AI environment capable of running secure internal copilots, document assistants, or analytics chatbots.
And perhaps most importantly: it builds capability inside your organisation.
Instead of outsourcing intelligence, you own it.
We’ve created a detailed reference architecture and Bill of Materials (BOM) showing how to build an on-prem or VPC-hosted LLM environment. From GPU selection and inference gateways to deployment automation and monitoring.
If you’re exploring how to bring AI safely and affordably inside your organisation, get in touch.
We’ll walk you through the setup and help you design a stack that fits your business, not your GPU supplier.