Retrieval-augmented generation is one of the most practical ideas in AI engineering. Here is what it actually does, where it works, and where it still falls short.
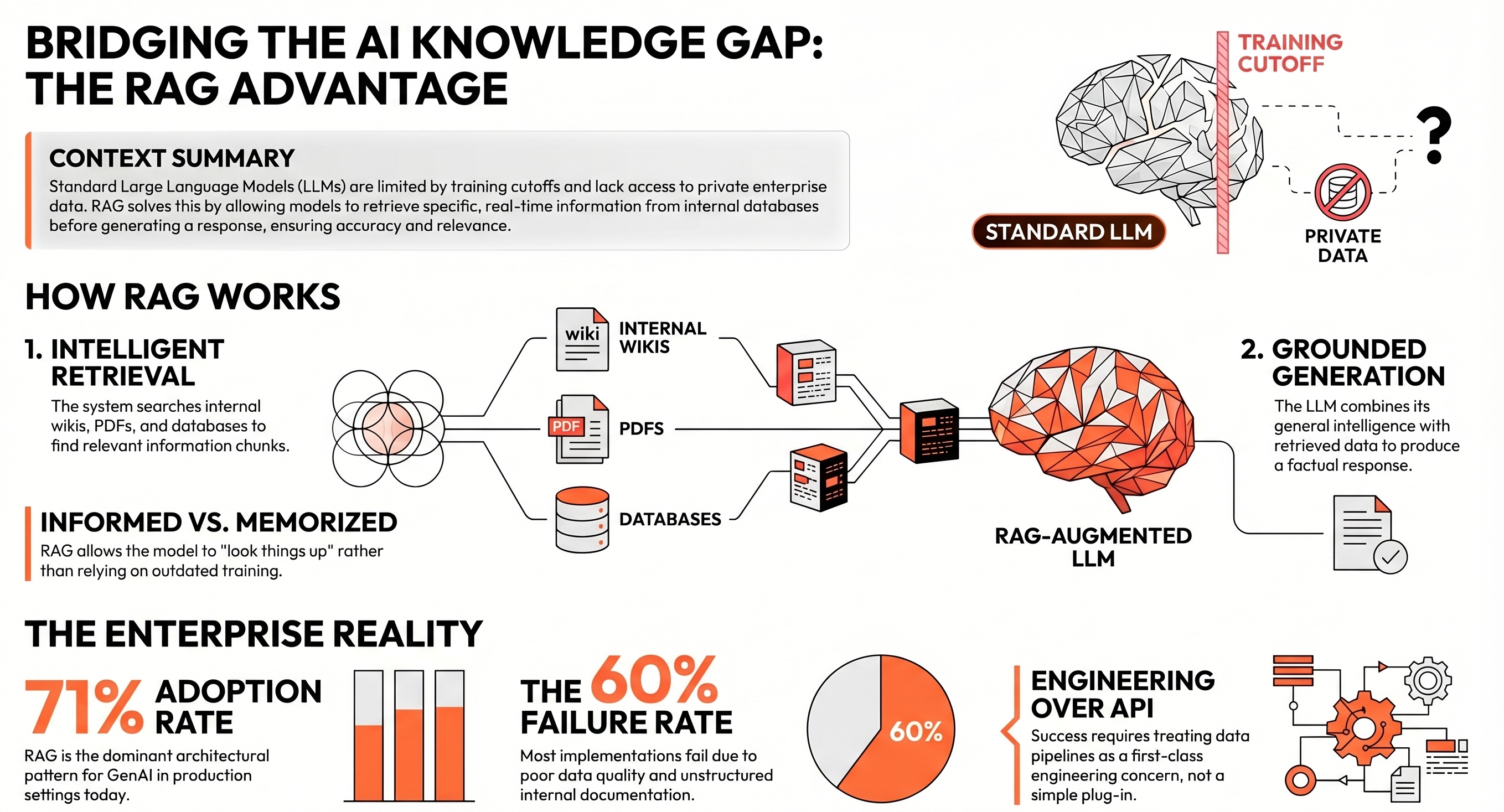
Every language model has a knowledge cutoff. It was trained on data up to a certain point, it knows nothing that happened after that, and it has no awareness of what is in your internal documents, your product database, your company policies, or last quarter's financial reports. When you ask it something that requires that knowledge, it either makes something up or tells you it does not know.
This is one of the most significant practical limitations of LLMs in enterprise settings, and it is the problem that retrieval-augmented generation (RAG) was built to address. It is not a new model, a new training approach, or a different architecture. It is a pattern for giving a model access to the right information at the right moment, so that it can generate a response grounded in reality rather than in its training data alone.
Understanding RAG is increasingly essential for anyone making decisions about AI systems in their organisation. It is behind a large proportion of the practical enterprise AI applications being built today, and knowing how it works helps you understand both its considerable value and its genuine limitations.
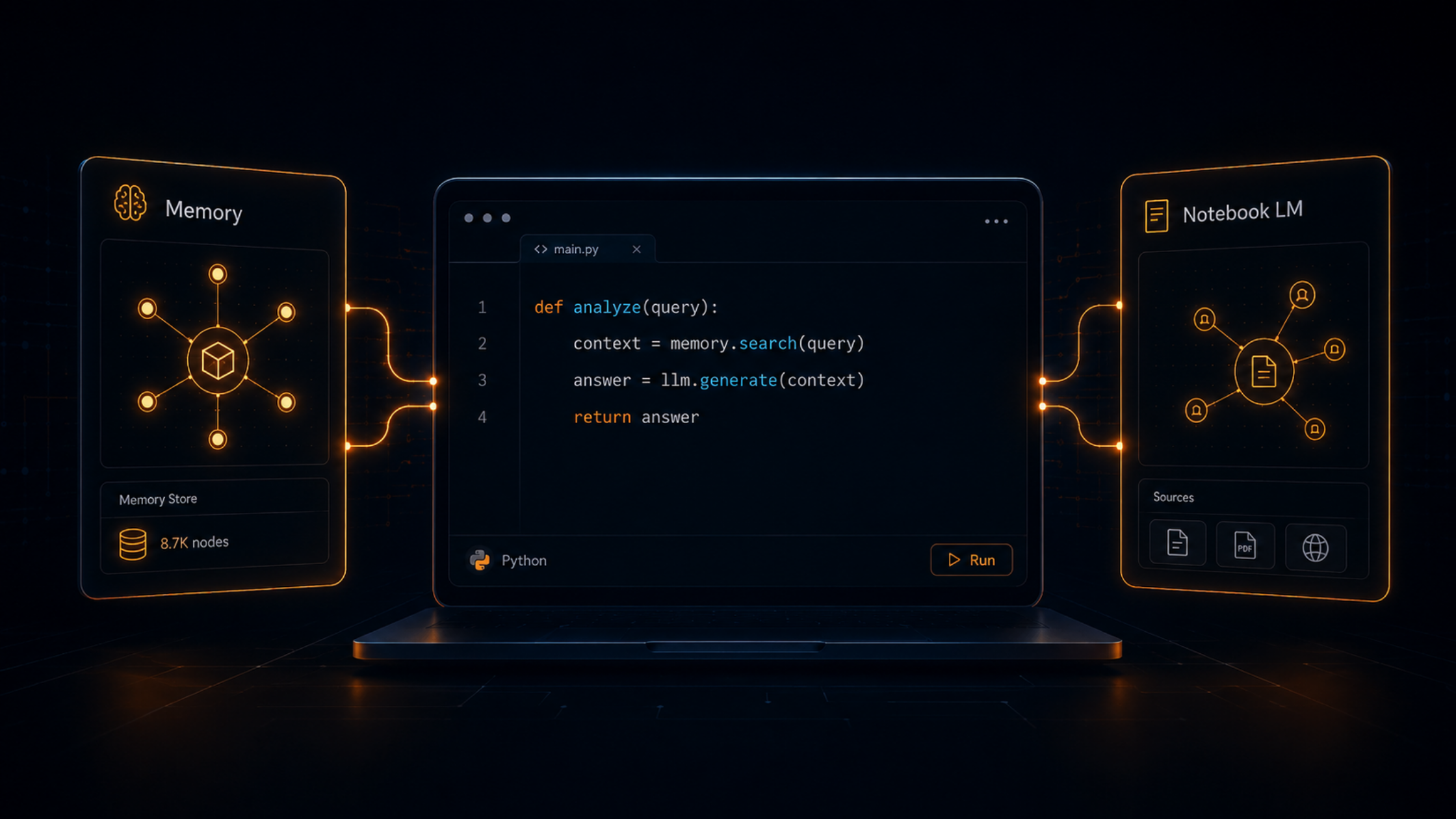
At its simplest, RAG works in two steps. When a user asks a question, the system first searches a knowledge base; your documents, your database, your internal wiki to find the most relevant information. It then passes that information to the language model alongside the original question. The model generates a response using both its general knowledge and the specific content it just retrieved.
Think of it as the difference between asking a colleague who has memorised your company handbook versus asking one who can look things up in real time. The colleague who can look things up is more likely to give you an accurate, current answer. The memorised version may confidently tell you something that was true two years ago.
RAG does not make the model smarter. It makes the model better informed by giving it the right documents to reason over at the moment it needs them.
The knowledge base can be almost anything: PDF documents, internal wikis, product catalogues, customer support logs, regulatory filings, code repositories. What matters is that it is indexed and searchable in a way that allows the system to retrieve relevant chunks quickly and accurately. In most implementations, this is done using vector search converting text into numerical representations and finding the closest matches to the incoming query.
The reason RAG has become so central to enterprise AI is straightforward: most of the valuable knowledge inside an organisation is not in the public domain. It is in internal documents, proprietary systems, and accumulated institutional knowledge that no language model was ever trained on. Without a mechanism to bring that knowledge into the conversation, LLMs are limited to what they learned during training which excludes almost everything that makes your organisation distinct.
Healthcare providers use RAG to give clinical AI systems access to current treatment guidelines and patient records, ensuring responses reflect the latest evidence rather than data from a model training run. Legal teams use it to query large contract libraries without manually reviewing every document. Enterprise support tools use it so that customer-facing AI can pull from current product documentation rather than hallucinating answers.
The pattern has become widespread. According to McKinsey's latest State of AI, 71% of organisations report regular use of generative AI, and RAG is the dominant architectural pattern behind production deployments. Vendors like Workday and ServiceNow have integrated it into their platforms. Yet the same research notes that only 17% attribute more than 5% of EBIT to generative AI a gap that largely comes down to implementation quality rather than technology readiness.
RAG is not a guaranteed solution.
In practice, between 40 and 60 percent of RAG implementations fail to reach production, according to research tracking enterprise AI deployments. The failure modes are well understood at this point, even if they are not always anticipated.
The most common issue is data quality. RAG is only as good as the knowledge base it retrieves from. Documents that are poorly structured, out of date, inconsistently formatted, or missing key sections produce poor retrieval results and poor retrieval results produce poor answers. An AI system that says 'See Appendix B' when Appendix B is not in the index is not a useful system. Organisations that treat their internal knowledge as a secondary concern tend to discover this the hard way.
A RAG system built on messy, unstructured, or outdated internal documents will produce messy, unreliable answers. The technology is sound; the data is usually where the problem lives.
A second issue is retrieval precision. The system needs to find the right chunks of information from potentially millions of documents, and it needs to do so consistently across a wide range of query types. Simple semantic search works well for straightforward questions but can struggle with complex, multi-step queries that require reasoning across several sources. More advanced implementations use hybrid search combining semantic matching with keyword search and metadata filtering to handle this diversity.
There is also a latency consideration. Retrieval adds steps to the process, which adds time. For use cases where response speed matters customer-facing interfaces, live support tools this trade-off needs to be designed for explicitly. It is manageable, but it requires thought.
The teams that get this right tend to share a few characteristics. They treat the knowledge infrastructure; the ingestion pipeline, the indexing strategy, the metadata structure, the freshness of the documents as a first-class engineering concern, not an afterthought. They test retrieval quality rigorously, with a curated set of questions and expected answers, before deploying to users. They build feedback loops so that poor retrievals can be identified and addressed over time.
They also match the complexity of the RAG architecture to the complexity of the use case. A simple document Q&A tool does not need the same architecture as a multi-step research agent that reasons across a dozen internal systems. Over-engineering a straightforward use case wastes time and money; under-engineering a complex one produces a system that fails silently when it matters most.
The field is also evolving quickly. What started as a relatively static pattern, retrieve, then generate is moving toward more adaptive systems that can plan their own retrieval strategies, decide when to retrieve at all, validate the information they find before using it, and pull from multiple sources in sequence. These agentic RAG systems significantly increase what is possible, but they also introduce new failure modes that require careful design and monitoring.
If you are building AI systems that need to work with your internal knowledge; policies, products, client data, operational documentation.
RAG is almost certainly part of the answer. The alternative, which is either retraining a model on your data or hoping the model knows enough from its training, is either prohibitively expensive or unreliable for anything that changes frequently. RAG offers a practical middle path: the intelligence of a well-trained model, applied to the specific knowledge your organisation actually holds.
The honest caveat is that building it well requires more than selecting a vector database and connecting it to an API. It requires thinking carefully about what knowledge your system needs access to, how that knowledge is structured, how it will be kept current, and how you will know when retrieval is failing. Those are not particularly glamorous engineering problems, but they are the ones that determine whether the system is useful in practice.
The organisations making the most progress with RAG are the ones that have taken those questions seriously from the start. The ones that have not tend to find themselves with a demo that works beautifully on clean data and falls apart in production.